
mnist 데이터셋에서 X의 형태 바꾸기
데이터의 형태 바꾸기
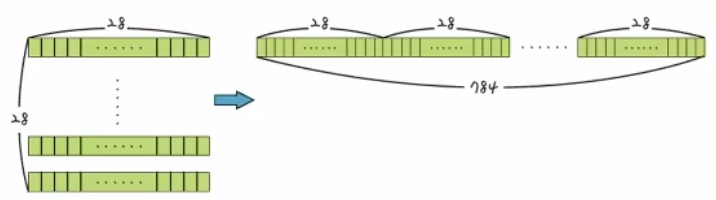
28 * 28의 데이터를 1*784 형태처럼 한 줄로 만든 후 이를 딥러닝 모델에 입력
X_train = x_train.reshape(60000, 784)
X_test = x_test.reshape(10000, 784)X_train
28×28 형태인 x_train 데이터를 1×784로 바꾸는 명령어
reshape: 넘파이의 명령어이고 데이터의 형태를 원하는 대로 바꿀 수 있다.
(60000, 28, 28) → (60000, 784)로 데이터의 형태가 된다.
X_test
(10000, 28, 28) → (10000, 784)로 데이터의 형태가 된다.
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')정규화를 하기 위해 데이터를 0~1 사이의 값으로 바꿔 준다.
정수형 >> 실수형
정규화하는 이유는 데이터의 특성을 더 잘 드러나도록 하기 위해
이렇게 정규화하면 정규화하지 않은 데이터보다 학습이 잘 이루어질 수 있다
X_train /= 255
X_test /= 255앞에서 mnist 데이터의 각 형태를 살펴봤듯이 검은색은 0, 흰색은 255, 회색은 1~254 사이의 값으로 이루어져 있다
이를 0~1 사이의 값으로 바꾸는 방법은 바로 255로 나누는 것
print("X Training matrix shape", X_train.shape)
print("X Testing matrix shape", X_test.shape)으로 출력

mnist 데이터셋에서 Y의 형태 바꾸기
- 몇 번째라는 식으로 알려주면 인공지능은 더 높은 성능으로 분류할 수 있다
- 그래서 예측이 아닌 분류 문제에서는 대부분 정답 레이블을 첫 번째, 두 번째, 세 번째와 같이 순서로 나타내도록 데이터의 형태를 바꾼다
- 이때 사용하는 방법이 바로 원-핫 인코딩(one-hot incoding)
Y_train = to_categorical(y_train, 10)
Y_test = to_categorical(y_test, 10)
print("Y Training matrix shape", Y_train.shape)
print("Y Testing matrix shape", Y_test.shape)레이블을 원-핫 인코딩 형태로 변경하기 위해 to_categorical 함수를 사용
인공지능 모델 설계
- 우리가 설계하고 있는 인공지는 모델은 4개의 층으로 이루어져 있다
- 첫번째 층: 입력층 - 데이터를 넣는 곳
- 두번째와 세번째 층: 은닉층
- 네번째 층: 출력층으로 결과가 출력됨

model = Sequential()딥러닝에 사용할 모델(model)을 시퀀셜 모델(Sequential)로 정의함
model.add(Dense(512, input_shape=(784,)))Dense 함수의 첫 번째 인자는 해당 은닉층의 노드 수
두 번째 인자인 input_shape은 입력하는 데이터의 형태
model.add(Activation('relu'))렐루(relu) 활성화 함수 사용
model.add(Dense(256))다음 층으로 두 번째 은닉층을 256개의 노드로 구성
두 번째 은닉층은 입력받은 노드를 설정해 줄 필요가 없다
model.add(Dense(10))마지막 층을 추가하고 10개의 노드로 구성
최종 결괏값이 0부터 9까지의 수 중 하나로 결정
model.add(Activation('softmax'))각 노드에서 전달되는 값의 총 합이 1이 되도록 소프트맥스 함수를 사용
model.summary()모델이 어떻게 구성되었는지 살펴보는 함수

모델 학습
심층 신경망에 데이터를 흘려 보낸 후 정잡을 예측할 수 있도록 신경망을 학습하는 과정인 딥러닝이 필요하다.

model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])케라스는 심층 신경망의 학습하는 방법을 정하는 명령어를 제공해준다.
첫 번째로는 오차값을 계산하는 방법을 알려줘야 한다
이 인공지능은 이미지를 10개 중 하나로 분류해야 하므로 다중 분류 문제에 해당한다
그래서 categorical_crossentropy 방법을 사용
두 번째로는 오차를 줄이는 방법을 알려줘야 한다
오차를 줄이기 위해 옵티마이저(optimizer)를 사용
옵티마이저?
딥러닝을 통해 인공지능 모델을 학습시킬 때 발생하는 오차를 줄이기 위해 경사 하강법이라는 알고리즘을 사용한다.
이때 경사 하강법을 어떠한 방식으로 사용할지 다양한 알고리즘이 있는데 그러한 알고리즘들을 케라스에서 모아 놓은 것이 바로 옵티마이저 라이브러리
옵티마이저의 종류에는 아담(adam)뿐만 아니라 확률적 경사 하강법(SGD) 등이 있다.
마지막으로는 학습 결과를 어떻게 확인할지 알려줘야 한다
정확도(accuracy)는 실제 60,000개 데이터의 예측 결과와 실제 값을 비교해 본 후 정답 비율을 알려준다
model.fit(X_train, Y_train, batch_size=128, epochs=30, verbose=1)첫 번째로 입력할 데이터를 정한다
두 번째로 배치 사이즈(batch_size)를 정한다
- 배치 사이즈: 인공지능 모델이 한 번에 학습하는 데이터의 수
세 번째로 에포크(epochs)를 정한다
- 에포크: 모든 데이터를 1번 학습하는 것
마지막은 결괏값을 출력하는 방법
verbose 값은 0, 1, 2 중 하나로 결정한다.
| verbose 값 | 의미 |
| 0 | 아무런 표시를 하지 않음 |
| 1 | 에포크별 진행 사항을 알려줌 |
| 2 | 에포크별 학습 결과를 알려줌 |


모델 정확도
score = model.evaluate(X_test, Y_test)케라스의 evaluate 함수는 모델의 정확도를 평가할 수 있는 기능
두 가지 데이터를 넣어야 한다
- 첫 번째 데이터는 테스트할 데이터
- 두 번째 데이터는 테스트할 데이터의 정답
evaluate 함수에 데이터를 넣으면 두 가지 결과를 보여준다
- 첫 번째는 바로 오차값(loss)
- 오차값은 0~1 사이의 값
- 0이면 오차가 없는 것
- 1이면 오차가 큰 것
- 두 번째는 정확도(accuracy)
- 0과 1 사이의 값
- 1에 가까울 수록 정답을 많이 맞춘 것
print('Test score:', score[0])
print('Test accuracy:', score[1])
모델 학습 결과 확인
predicted_classes = np.argmax(model.predict(X_test), axis=1)argmax 함수는 여러 데이터 중에서 가장 큰 값이 어디에 있는지를 나타낸다
argmax 함수를 사용하기 위해서는 열 중에서 가장 큰 것을 고를지, 행 중에서 가장 큰 것을 고를지 알려줘야 한다.
이때 기준을 정해주는 것이 바로 axis
- axis=0 각 열(세로)에서 가장 큰 수를 고르는 것
- axis=1 각 행(가로)에서 가장 큰 수를 고르는 것
correct_indices = np.nonzero(predicted_classes == y_test)[0]실제 값과 예측 값이 일치하는 값을 찾아내어 correct_indices 변수에 저장하는 과정
논리 연산자를 사용하여 예측 값( predicted_classes)과 실제 값( y_test)을 비교
논리 연산의 결과 두 값이 같으면 1(참), 같지 않으면 0(거짓)이 나온다
같은 값을 찾기 위해서 10,000개의 수 모두를 하나하나 확인하는데 넘파이 함수의 nonzero를 사용한다
incorrect_indices = np.nonzero(predicted_classes != y_test)[0]인공지능이 예측하지 못한 값
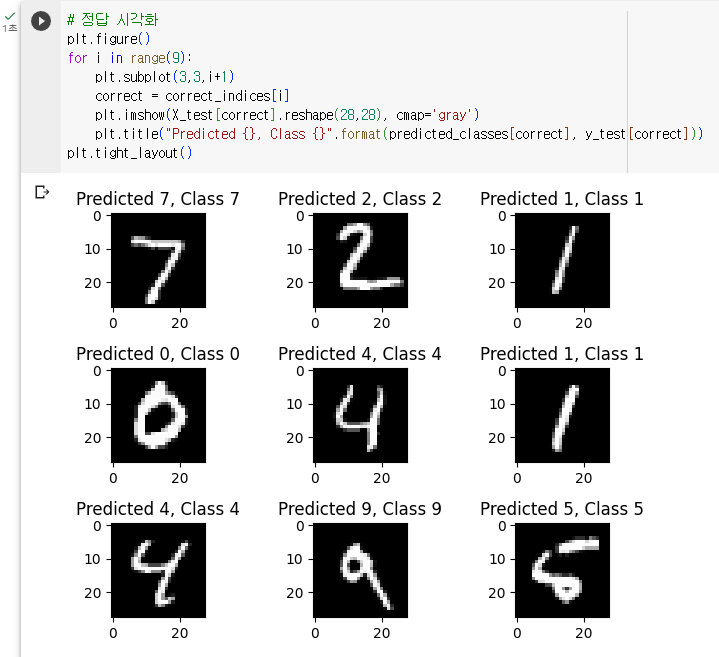
잘 예측한 데이터 보기
plt.figure()
for i in range(9):
plt.subplot(3,3,i+1)
correct = correct_indices[i]
plt.imshow(X_test[correct].reshape(28,28), cmap='gray')
plt.title("Predicted {}, Class {}".format(predicted_classes[correct], y_test[correct]))
plt.tight_layout()- figure 함수로 그림 그린다
- for 반복문으로 9개 그린다
- subplot 함수는 그림의 위치를 정해주는 함수
- 첫 번째 인자: 그림의 가로
- 두 번째 인자: 그림의 세로
- 세 번째 인자: 순서
- 반복될 때 마다 correct 변수에 넣어준다.
- imshow 함수는 어떤 이미지를 보여줄지에 대한 내용을 담고 있다
- 첫 번째 반복에서는 X_test 변수에 들어 있는 첫 번째 그림을 가져온다.
- reshape(28,28) 함수로 다시 28×28의 형태로 바꿔준다.
- cmap='gray' 회색으로 나타내준다
- title 함수는 그림 설명을 넣는 코드
- 그림을 보여주기 위해 tight_layout 함수 사용
잘 예측하지 못한 데이터 보기
plt.figure()
for i in range(9):
plt.subplot(3,3,i+1)
incorrect = incorrect_indices[i]
plt.imshow(X_test[incorrect].reshape(28,28), cmap='gray')
plt.title("Predicted {}, Class {}".format(predicted_classes[incorrect], y_test[incorrect]))
plt.tight_layout()
본 후기는 정보통신산업진흥원(NIPA)에서 주관하는 <AI 서비스완성! AI+웹개발 취업캠프 - 프론트엔드&백엔드> 과정 학습/프로젝트/과제 기록으로 작성되었습니다.
'코딩캠프 > AI 웹개발 취업캠프' 카테고리의 다른 글
| [AI 웹개발 취업캠프] 60Day - 프로젝트 11일차 (0) | 2023.10.16 |
|---|---|
| [AI 웹개발 취업캠프] 34Day - 전염병 예측/숫자 생성 인공지능 만들기 (0) | 2023.09.01 |
| [AI 웹개발 취업캠프] 32Day - 파이썬과 코랩(예비군/3일차) (0) | 2023.08.30 |
| [AI 웹개발 취업캠프] 31Day - 딥러닝 이해_2(예비군/2일차) (1) | 2023.08.29 |
| [AI 웹개발 취업캠프] 30Day - 딥러닝 이해(예비군/1일차) (0) | 2023.08.28 |